In Data Science
Web sites and mobile applications often use searches for words or phrases that a user freely enters on the keyboard (rather than selecting for example from a list) to find relevant information.

Management

Fuzzy search in relational databases
Naturally, the user may make mistakes and typos. In this case, full-text search, full-text indexes that are implemented in most databases do not produce the expected result and are practically useless. Such functionality is increasingly being implemented based on elasticsearch.
Solutions using elasticsearch have one major disadvantage - a very high probability of mismatch between the underlying database, such as PostgreSQL, MySQL, mongodb and elasticsearch, in which the search indexes are stored.
The ideal would be to have a "bridge" that would take over the data reconciliation function in case the search engine database is unavailable while the primary database is being updated. But I haven't found any implementation of such a bridge yet. For example one of the mongodb and lucene bundle projects talks about this problem.
How to solve this problem in practice? Well, there is no way. If the data are not very big, the database is simply reindexed by a timer. If the database is big and it is often impossible to reindex it, everything remains as it is, uncoordinated.
Hopefully sustainable "bridges" that will steadily update indexes in elasticsearch or lucene will appear sooner or later. Right now there is a need to find a workable solution.
One option is to use a single database for storing data and for searching. About using elasticsearch as such a single database, there was a consensus in almost all the discussions on the forums that this solution is not suitable. Therefore, I started looking for a database in which I could create full-text indexes that supported fuzzy search. Since the main engine for such indexes, lucene, is developed in java, the range of databases in which I searched for such a possibility was clearly outlined.
As it turned out, there are at least two solutions that use the lucene library and are application-level poduction ready: they are orientdb and h2.
In orientdb the fuzzy full-text search is very easy to work with:
create class language
create property language.message string
create index language.message on language(message)
fulltext engine lucene metadata {
"analyzer": "org.apache.lucene.analysis.en.LanguageAnalyzer"
}
select * from language where message lucene 'Habfdhb~0.5' limit 2
In h2 it is a bit more complicated, because the index is a separate table to which the main table must be linked. But a bit more complicated does not mean complicated.
CREATE ALIAS IF NOT EXISTS FTL_INIT FOR
"org.h2.fulltext.FullTextLucene.init";
CALL FTL_INIT();
DROP TABLE IF EXISTS TEST;
CREATE TABLE TEST(ID INT PRIMARY KEY, FIRST_NAME VARCHAR,
LAST_NAME VARCHAR);
CALL FTL_CREATE_INDEX('PUBLIC', 'TEST', NULL);
INSERT INTO TEST VALUES(1, 'John', 'Wayne');
INSERT INTO TEST VALUES(2, 'Elton', 'John');
SELECT * FROM FTL_SEARCH_DATA('John', 0, 0);
SELECT * FROM FTL_SEARCH_DATA('LAST_NAME:John', 0, 0);
Already after publication, fuzzy search was supported by ArangoDB. Unfortunately the documentation for this functionality is not very detailed. That's why I'm making notes of what I've managed to "dig up".
First, you should create an analyzer with required search parameters. For example this one (in arangosh):
require('@arangodb/analyzers').save('fuzzy_search_bigram','ngram',{"min": 2,"max": 2,"preserveOriginal": false},["position", "frequency", "norm"] );
Next, create a view - this can be done in the ArangoDB web interface. The created view will have an empty links object, which will store links to the indexed tables and fields. Add a link to the indexed collection to this object:
"links" : {
"" : {
"includeAllFields": true,
"fields" : {
"title" : { "analyzers" : [ "fuzzy_search_bigram"] },
"description" : { "analyzers" : [ "fuzzy_search_bigram"] }
}
}
}
And request data from the created view:
A second way to implement ArangoDB's odd search can be to integrate with elasticsearch. Unlike integration with other databases, which do not ensure data consistency, in case a failure occurs on the data path from the database to elasticsearch, a fault-tolerant system can be built with ArangoDB, as ArangoDB has the ability to query all changes from any point in time in the past to the current point in time.
MasterDB + Elastic stack
As for MasterDB + Elastic stack, I'd suggest accepting data in the application (admin) when adding/modifying/deleting it via Event Sourcing. I.e. define Accept[Insert/Update/Remove]<TModel>(TModel model) method, which will add/modify/delete your domain model properly to the elasticity index with all the necessary relationships. Only this method must be implemented in such a way that no state of the index or masterDB affects its result - the result must always be the same.
Add, change products, manufacturers and categories of the online shop.
We'll make two methods:
AcceptInsert: As a result, the product is added to the index with a check on the SourceId field (Id in your MasterDB). The product has a manufacturer (we can't edit manufacturers, only add them) which is copied into an attached document, and the category is searched in the index by SourceId.(Product product) AcceptInsert: As a result, the category is added to the index with a check on the SourceId field.(Category category)
After saving the product in the admin, call the AcceptInsert<Product> method. Or we make a shell that updates index every n-minutes, working with source documents by some filter.
Fuzzy logic in database: theory
Fuzzy query mechanisms (fuzzy queries, flexible queries) for relational databases based on Zadeh's fuzzy set theory were first proposed in 1984 and subsequently developed in the works of D. Dubois and G. Prada.
Why it's needed
Much of the data processed in modern information systems is clear, numerical in nature. However, inaccuracies and uncertainties are often present in queries to databases that humans attempt to formulate. Not surprisingly, when a query in an Internet search engine results in multiple links to documents ordered by relevance (or relevance) to the query. This is because textual information is inherently vague and ambiguous due to semantic ambiguity of language, synonyms, etc.
With information system databases, or Crisp Databases, the situation is different. Suppose, for example, that the following information needs to be extracted from a database:
- "Get a list of young employees with low salaries".
- "Find offers for low-cost housing close to the city centre".
Here the statements "Young", "Not very high", "Not very expensive", "Close" have a vague, imprecise character, although the salary is defined to the ruble, and the distance of the flat to the centre is accurate to the kilometre. The reason for this is that in real life, we operate and reason with vague, imprecise categories. Such queries cannot be performed with SQL language tools. This is where the concept of fuzzy queries comes in.
Let's demonstrate the limitations of fuzzy queries with the following example. Suppose you want to get information about all sales managers under 25 years old, whose annual sales amount exceeded 200 thousand for a region. This query can be written in SQL as follows
select FIO from Managers
where (Managers.Age <= 25 AND Managers.Sum > 200000 AND Managers.RegionID = 1)
A 26 year old Sales Manager with a yearly sales amount of $400000 or a 19 year old Sales Manager with a yearly sales amount of 198 thousand would not find it in the query, even though their characteristics almost match the query.
Fuzzy queries help you deal with these kinds of "missing" information problems.
How it works
The mechanism of fuzzy queries is based on fuzzy sets theory, the main details of which were outlined in the previous article Fuzzy logic - the mathematical basics.
Let's consider the most common ways to generate new linguistic terms based on a basic term set. This is useful for constructing a variety of semantic constructions that strengthen or weaken statements, e.g: "very high price", "approximately middle-aged", etc. For this purpose, there are linguistic modifiers (linguistic hedges) that strengthen or weaken a statement. The linguistic hedges that strengthen or weaken statements include the Very modifier, and the weakening ones include the More-or-less modifier, or the more-or-less modifier, whose fuzzy sets are described by membership functions of the form:
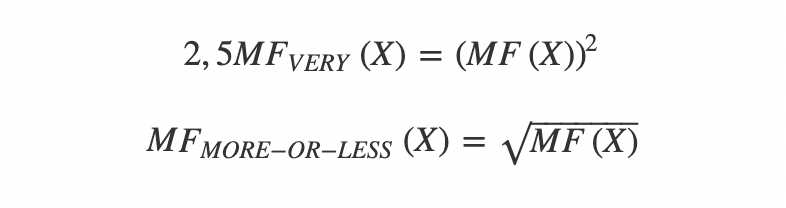
For the example, let's formalise the fuzzy concept "Age of a company employee". This will be the name of the corresponding linguistic variable. Let's set for it the definition area X = [18; 70] and three linguistic terms - "Young", "Average", "Above Average". The last thing to do is to construct the membership functions for each linguistic term.
Let's choose trapezoidal membership functions with the following coordinates:
"Young" = [18, 18, 28, 34], "Medium" = [28, 35, 45, 50], "Above Average" = [42, 53, 60, 60].
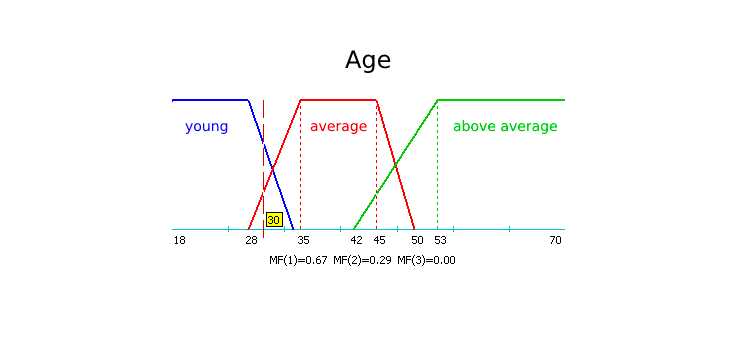
You can now calculate the degree to which an employee 30 years old belongs to each of the fuzzy sets:
MF[Young](30)=0.67; MF[Average](30)=0.29; MF[Above Average](30)=0.
The main requirement in constructing the membership functions is that the value of the membership functions must be greater than zero for at least one linguistic term.
Finally let's define a fuzzy negation operation (NOT): MF[NOT](X)=1-MF(X).
The above information is sufficient to construct and execute fuzzy queries.
Let's go back to the example of sales managers. For simplicity, let's assume that all necessary information is in one table with the following fields: ID - employee number, AGE - age and SUM (annual amount of transactions).
| ID | AGE | SUM |
|---|---|---|
| 1 | 23 | 120 500 |
| 2 | 25 | 164 000 |
| 3 | 28 | 398 000 |
| 4 | 31 | 489 700 |
| 5 | 33 | 251 900 |
| … | ||
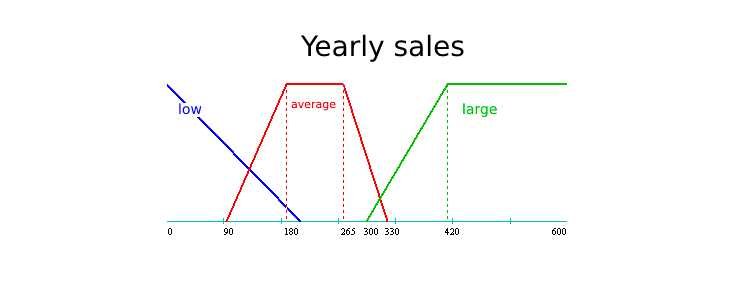
The linguistic variable "Age" was previously defined. Let's define another linguistic variable for the field SUM with area of definition X = [0; 600000] and the terms "Small", "Medium" and "Large" and similarly build membership functions for them:
"Small" = [0, 0, 0, 200000], "Medium" = [90000, 180000, 265000, 330000], "Large" = [300000, 420000, 600000, 600000].
You can make fuzzy queries on this table. For example, to get a list of all young sales managers with large annual amount of transactions, which in SQL-like syntax would be written as follows:
select * from Managers where (Age = "Young" AND Sum = "Large")
Calculate for each record an aggregate value of belonging function MF (using fuzzy "AND" operation) and get the result of fuzzy query:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 3 | 28 | 398 000 | 0,82 |
| 4 | 31 | 489 700 | 0,50 |
Entries 1,2,5 are not included in the query result because the value of membership function for them is zero. There are no records in the table that exactly meet the query (MF=1). A sales manager of 28 years and an annual sum of 398000 corresponds to a query with an identity function of 0.82. In practice, it is common to enter an accessory function threshold above which records are included in the result of a fuzzy query.
A similar fuzzy query could be formulated as follows:
select * from Managers where (Age <= 28 AND Sum >= 420000)
Its result is empty. However, if we widen the scope of age in the query slightly, we risk missing other employees with a slightly higher or lower age. Therefore, we can say that fuzzy queries allow us to extend the scope of the search according to the initial human constraints.
Using fuzzy modifiers, more complex queries can be generated:
select * from Managers where (Age = "more-or-less Average" AND Sum = "Average")
Result:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 5 | 33 | 251 900 | 0,85 |
Often it is not linguistic variables that you want to manipulate, but fuzzy analogues of exact values. To do this, there is the fuzzy relation "ABOUT" (e.g. "Price around 20"). To implement such fuzzy relations, a fuzzy set is similarly constructed with an appropriate membership function, but on some relative interval (e.g., [-5; 5]) to avoid context dependency. When calculating the membership function of the fuzzy relation "About Q" (Q is some distinct number), we scale it by the relative interval.
Let's illustrate the above with an example of a table of securities data. Let it have the following fields: PRICE (security price), RATIO (price-to-earnings ratio), AYIELD (average income for the last quarter, average yield, %).
| ID | PRICE | RATIO | AYIELD |
|---|---|---|---|
| 1 | 260 | 11 | 15,0 |
| 2 | 380 | 5 | 7,0 |
| 3 | 810 | 6 | 10,0 |
| 4 | 110 | 9 | 14,0 |
| 5 | 420 | 10 | 16,0 |
Suppose we need to find securities to buy not more expensive than $150, with a yield of 15% and a price-to-earnings ratio of 11. This is equivalent to the following SQL query:
select * FROM some_table where ((PRICE<=150) AND (RATIO=11) AND (AYIELD=15))
The result of such query will be empty.
Then let's formulate the same query in a fuzzy form using the "ABOUT" relation:
select * FROM some_table
where ((PRICE = "ABOUT 150") AND (RATIO= "ОкоABOUTло 11") AND (AYIELD="ABOUT 15"))
Let's build a fuzzy set for the "OKOLO" relation in the relative interval [-5; 5]. It will be a trapezoid with coordinates [-2, -1, 1, 2].
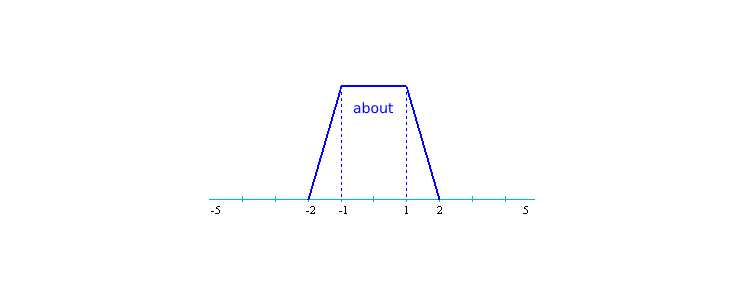
Let's calculate the value of the fuzzy query "Price about 250" for the price of 380. Preliminarily specify the definitions of each linguistic variable: PRICE - [0; 1000], RATIO - [0; 20], AYIELD - [0; 20]. Scale the value of 130 (obtained as the difference between 380 and 250) by the interval [-5; 5], we obtain the value of x=1.3 and MF(1,3)=0.7.
By applying a fuzzy ABOUT relation to each PRICE, RATIO and AYIELD field and calculating the aggregate value of the membership function using the fuzzy AND operation, we get the following query result.
| ID | PRICE | RATIO | AYIELD | MF |
|---|---|---|---|---|
| 1 | 260 | 11 | 15,0 | 1 |
| 4 | 110 | 9 | 14,0 | 0,9 |
The disadvantage of fuzzy queries is the relative subjectivity of the membership functions.
Applications of fuzzy logic in databases
Fuzzy queries are promising to use in areas where information is selected from databases using qualitative criteria and fuzzy conditions, such as Direct Marketing.
In direct marketing, the stage of identifying the target audience for which various direct marketing tools will be used is very important. For example, direct mail is used in the promotion of goods and services to organisations and individuals. However, in order to maximize the effect of direct mail, a careful choice of recipients is necessary. If the choice of addressees is liberal, direct marketing costs will increase unnecessarily, if it is too strict, a number of potential customers will be lost.
For example, a company is running a promotion among its customers about new services via direct mail. The marketing service has found that the new service will be of most interest to middle-aged men, fathers of families with above-average annual incomes. To get a list of recipients to the customer database is likely to make the following request: select all males aged 40 to 55 years, with at least 1 child, an annual income of 20 to 30 thousand dollars. Such precise query criteria may exclude a lot of potential clients: a 39 year old man, father of three, with an income of 31 thousand dollars will not be included in the query results, although he is a potential consumer of a new service.
Similarly, fuzzy queries can be used when selecting travel services, selecting real estate properties.
The fuzzy query tool allows you to reconcile formal criteria and informal requirements for the range of potential customers and set the intervals for selecting potential customers as fuzzy sets. In this case clients not satisfying any criterion can be selected from the database, if they have a good performance on other criteria.
References
- Dubois D., Prad G. Opportunity Theory. Applications to Knowledge Representation in Computer Science
- Ribeiro R.A., Moreira A.M. Fuzzy Query Interface for a Business Database // International Journal of Human-Computers Studies, Vol. 58 (2003), PP. 363-391.
- Dubois D., Prade H. Using Fuzzy Sets in Database Systems: Why and How? // Proc. of 1996 Workshop on Flexible Query-Answering systems (FQAS'96), Denmark, May 22-24, 1996, PP. 89-103.