In Data Science
Machine learning is actively used in many areas of our lives. Algorithms help us recognise traffic signs, filter spam, recognise our friends' faces on facebook, even help us trade on stock exchanges. The algorithm makes important decisions, so you need to make sure it cannot be fooled.

Management

First, here are the terms used in the security topic of machine learning algorithms:
- Adversarial example - a vector given as input to an algorithm on which the algorithm produces an incorrect output.
- Adversarial attack - an action algorithm that aims to obtain an Adversarial example.
To understand the problem of Adversarial examples, let's recall one of the machine learning tasks - learning with a teacher when classifying. In this task, we have object-tag pairs and we have to learn how to predict the value for new objects.
If we consider this task from a geometric point of view, we need to partition the space in such a way that the "correct" class is predicted on the new object. Moreover, if we had a general population of data (e.g. for a set of handwritten MNIST digits to have all possible images of all digits), then this hyperplane could be drawn perfectly under the condition of class separability. But since there is most often no general population, we use machine learning algorithms to solve this problem - to approximate the "ideal" hyperplane as closely as possible with the data we have.
Any deviation of the hyperplane from the ideal hyperplane generates a "gap" in which objects are classified incorrectly. This is why examples such as the panda being classified as a gibbon appear. And the attacker's task comes down to altering the vector of object parameters so that it falls into that "gap".
Examples of adversarial attacks
There is a neural network that detects a face in a photo. It successfully completes the task (the image on the left). But after adding a little noise to this photo (the image on the right), the algorithm on the resulting adversarial example (the image in the centre) no longer detects a face in the image.

Overfitting adversarial training: example of adversarial attack
This example, demonstrated in the article "Adversarial Attacks on Face Detectors using Neural Net based Constrained Optimization", is interesting because many real face detection systems use neural network approaches to detect faces. A person will not notice the difference when looking at both images.
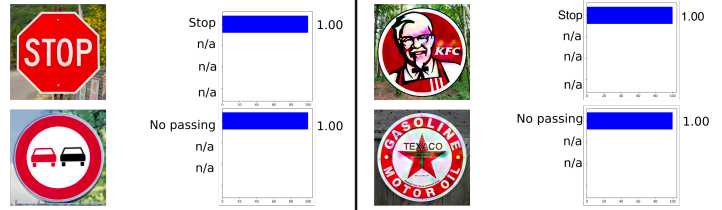
The following example is taken from automotive, namely the recognition of road signs. The interesting thing about this example is that it doesn't have to be an object even close to the one the network was trained on. For example, in paper "Rogue Signs: Deceiving Traffic Sign Recognition with Malicious Ads and Logos", it is shown that the adversarial example of a KFC sign will be recognized by the initial neural network as a STOP sign with 100% probability.
Overfitting adversarial training: example of adversarial attack
Many may have doubted the use of adversarial examples in the real world, because the previous examples were tested on the computer, while in real life such an object is hardly possible to obtain. But this is not the case. In the work "Synthesizing Robust Adversarial Examples" was shown that made on a computer adversarial example can be successfully printed on a 3D printer, and the algorithm will make the same errors as in the computer simulation.

Overfitting adversarial training: example of adversarial attack
Here you see a turtle printed on a 3D printer which was not recognised as a turtle at any angle.
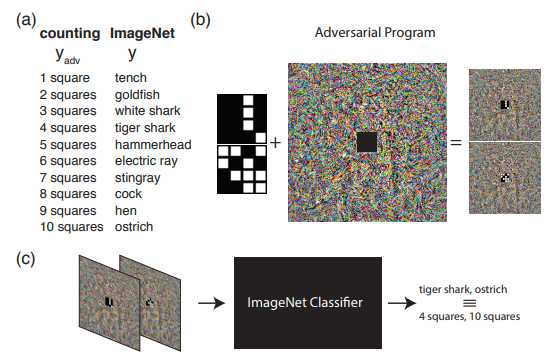
The following example, however, shows what can be done if we go beyond the usual understanding of the adversarial attack. Namely, to reprogram the original network to use its own payload. In other words, we are trained to use someone else's neural network to solve the problem posed by the attacker. For example, the work "Adversrial Reprogramming of Neural Network" demonstrated how a network trained on ImageNet perfectly counted the number of squares in an image and recognized the numbers from the MNIST set.
Overfitting adversarial training: example of adversarial attack
The image shows the Adversarial Reprogramming algorithm, which we recommend to learn more about in the original article.
In this article we would like to talk specifically about ways of generating Adversarial examples, and in the second article we will move on to ways of securing and testing machine learning algorithms.
Protection from adversarial attacks
First of all, let us immediately clarify one point - it is impossible to be completely protected from such an effect, and this is quite natural. After all, if we were to solve the problem of Adversarial examples completely, we would simultaneously solve the problem of building a perfect hyperplane, which, of course, cannot be done without having a general population of data.
The machine learning model can be defended in two stages:
- Training - we train our algorithm to respond correctly to Adversarial examples.
- Exploitation - we try to detect an Adversarial example in the exploitation phase of the model.
It's worth saying right away that we may work with the protection methods described in this article with the help of Adversarial Robustness Toolbox from IBM.
Overfitting adversarial training
If you ask a person who've just become acquainted with Adversarial examples a question: "How to protect yourself from this effect?", certainly 9 out of 10 people would say: "Let's add the generated objects to the training sample". This approach was immediately suggested in an article Intriguing properties of neural networks back in 2013. It was this article that first described this problem and the L-BFGS attack to get Adversarial examples.

Overfitting adversarial training: protection from adversarial attacks
This method is very simple. We generate Adversarial examples using different attacks and add them to the training sample at each iteration, thereby increasing the "resistance" of the model to Adversarial examples.
The disadvantage of this method is quite obvious: at each iteration of training, for each example, we can generate a very large number of examples, respectively, and the time to train the model increases many times.
To apply this method using the ART-IBM library is as follows.
from art.defences.adversarial_trainer import AdversarialTrainer
trainer = AdversarialTrainer(model, attacks)
trainer.fit(x_train, y_train)
Gaussian Data Augmentation
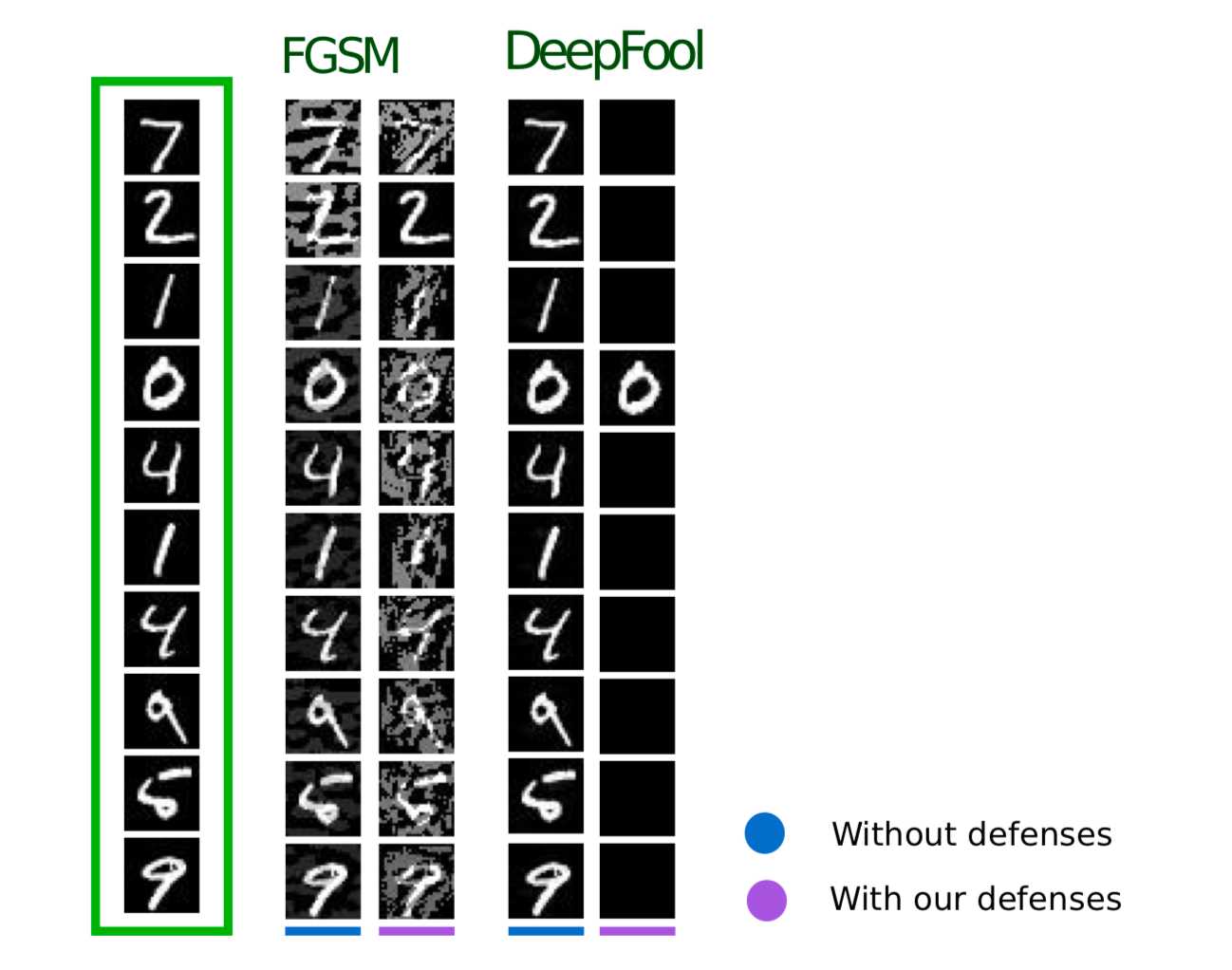
The next method, described in Efficient Defenses Against Adversarial Attacks, uses similar logic: it suggests adding additional objects to the training sample, but in contrast to Adversarial Training those objects are not Adversarial examples, but a little noisy objects in the training sample (Gaussian noise is used as noise, hence the name of the method). And, indeed, it seems very logical, because the main problem with the models is precisely their poor robustness to noise.
Overfitting adversarial training: Gaussian Data Augmentation
This method produces similar results to Adversarial Training while taking much less time to generate objects for training.
The method can be applied with the GaussianAugmentation class in ART-IBM:
from art.defences.gaussian_augmentation import GaussianAugmentation
GDA = GaussianAugmentation()
new_x = GDA(x_train)
Label Smoothing
The Label Smoothing method is very simple to implement, but nevertheless carries a fair amount of probabilistic meaning. We won't go into detail on the probabilistic interpretation of this method; it can be found in the original article Rethinking the Inception Architecture for Computer Vision. But to put it briefly, Label Smoothing is an additional type of regularization of the model in the classification problem, which makes it more robust to noise.
In fact, this method smoothes the labels of classes. By making them, say, not 1, but 0.9. Thus models are penalized during training for a very high "confidence" in the label for a particular object.
The application of this method to Python can be seen below:
from art.defences.label_smoothing import LabelSmoothing
LS = LabelSmoothing()
new_x, new_y = LS(train_x, train_y)
Bounded ReLU
When talking about attacks, many people may have noticed that some attacks (JSMA, OnePixel) depend on how strong the gradient is at one point in the input image. A simple and "cheap" (in terms of computational and time consumption) method called Bounded ReLU tries to solve this problem.
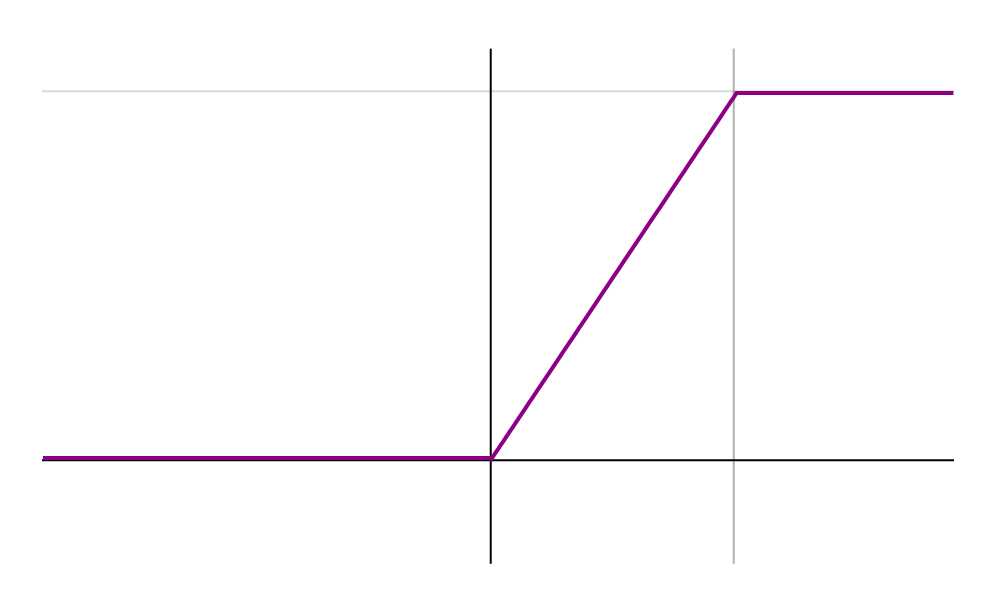
Overfitting adversarial training: Bounded ReLU
The essence of the method is as follows. Let's replace the function of activation ReLU in neural network by the same one but limited not only from below but also from above thus smoothing gradient maps and making it impossible to get a spike in specific points which doesn't allow to cheat algorithm by changing one pixel of the image.
begin{equation*}f(x)=
begin{cases}
0, x<0
x, 0 leq x leq t
t, x>t
end{cases}
end{equation*}
This method has also been described in Efficient Defenses Against Adversarial Attacks.
Building Model Ensembles
Overfitting adversarial training: building model ensembles
It is not difficult to fool one trained model. Fooling two models with one object at a time is even harder. But what if there are N models? This is what the model ensemble method is based on. We simply build N different models and aggregate their output into a single response. If the models are also represented by different algorithms, it is possible to fool such a system, but extremely difficult!
It is quite natural that implementing ensembles of models is a purely architectural approach, asking many questions (Which base models to take? How to aggregate outputs of base models? Is there a dependency between models? etc.). For this reason, this approach is not implemented in ART-IBM
Feature squeezing
This method, described in the article Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks, works at the model exploitation stage. It allows you to detect Adversarial examples.
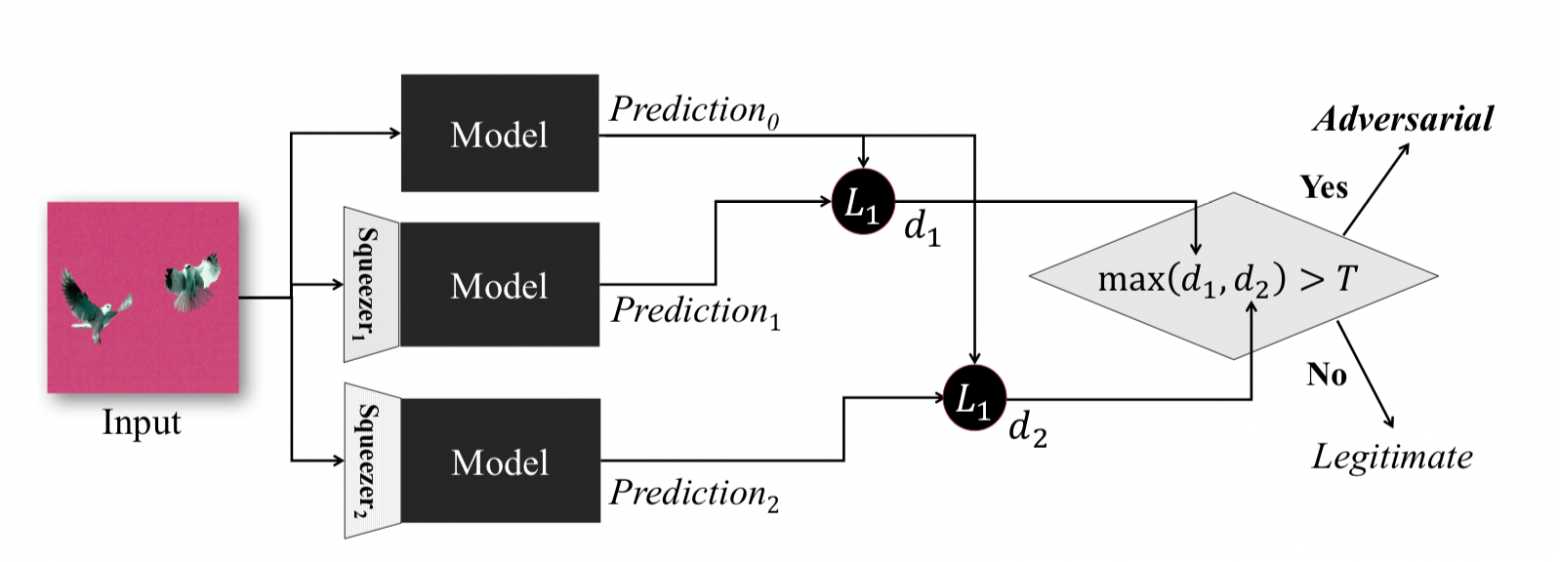
Overfitting adversarial training: Feature squeezing
The idea behind this method is the following: if you train n models on the same data, but with different compression ratios, the results will still be similar. An Adversarial example that works on the original network is highly likely to fail on additional networks. Thus having calculated the pairwise difference between the output of the original neural network and the auxiliary ones, selected the maximum of them and compared it to a pre-selected threshold, we can say that the object fed to the input is either Adversarial or absolutely valid.
Below, we present a method that allows us to obtain compressed objects using ART-IBM:
from art.defences.feature_squeezing import FeatureSqueezing
FS = FeatureSqueezing()
new_x = FS(train_x)
This concludes our discussion of security methods. But it would be wrong not to make one important point clear. If an attacker doesn't have access to the inputs and outputs of the model, he won't understand how the "raw" data is processed inside your system before entering the model. Then and only then will his attacks be limited to randomly scraping through the input values which is unlikely to produce the desired result.
Testing
Let us now talk about testing algorithms against Adversarial examples. The first thing to understand here is how we are going to test our model. If we are going to assume that in any way an attacker can gain full access to the entire model then we will have to test our model using WhiteBox attack methods.
Overfitting adversarial training: WhiteBox attack methods
In the other case we assume that an attacker will never have access to the innards of our model, but will still be able to influence the input data, albeit indirectly, and see the result of the model. In this case we should apply BlackBox attack methods.
Overfitting adversarial training: BlackBox attack methods
The general testing algorithm can be described with the following example:
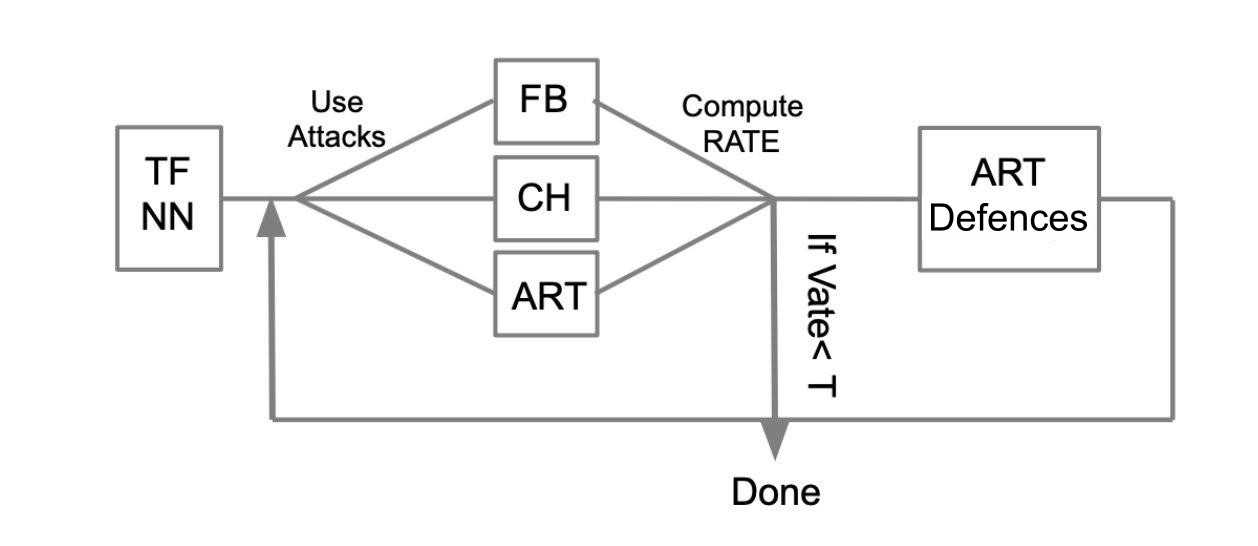
Overfitting adversarial training: testing algorithm
Suppose we have a trained neural network written in TensorFlow (TF NN). We expertly argue that our network can fall into the hands of an intruder by breaking into the system where the model resides. In such a case, we need to conduct WhiteBox attacks. To do this, we define a pool of attacks and frameworks (FoolBox - FB, CleverHans - CH, Adversarial robustness toolbox - ART) that enable these attacks. After that, counting how many attacks were successful, we calculate the Success Rate (SR). If we are satisfied with SR, we terminate the testing, otherwise, we apply one of the methods of protection, for example, implemented in ART-IBM. After that, we run the attacks again and calculate SR. We perform this operation in cycles, until we are satisfied with the SR.
Conclusions
At this point I would like to finish with the general information about attacks, defenses and testing machine learning models. To summarize the two articles, we can conclude the following:
- Don't believe in machine learning as some kind of miracle that can solve all your problems.
- When applying machine learning algorithms to your problems, think about how resistant the algorithm is to a threat such as Adversarial examples.
- Protect the algorithm both on the machine learning side and on the side of the system in which the model is being run.
- Test your models, especially in cases where the output of the model directly affects the decision being made
- Libraries such as FoolBox, CleverHans, ART-IBM provide a convenient interface for you to attack and defend machine learning models
Also in this article I would like to summarize the work with FoolBox, CleverHans and ART-IBM libraries:
- FoolBox is a simple and straightforward library for applying attacks on neural networks, supporting many different frameworks.
- CleverHans is a library that allows you to conduct attacks by changing many parameters of the attack, a bit more complicated than FoolBox, and supports fewer frameworks.
- ART-IBM is the only library among those described above that allows working with protection methods, supporting only TensorFlow and Keras for now, but developing faster than the others.
Here it is worth saying that there is another library for working with Adversarial examples from Baidu, but, unfortunately, it is suitable only for people who speak Chinese.